Introduction
When, I was learning Pytorch I had already two separate Python version (2.x and 3.x) together with a lot of packages installed on my machine and I did not want to risk messing up my laptop. So, I decided instead to use a docker image that provides me with the latest installation of Pytorch on a linux-based system and isolates it from everything else on my machine.
I didn’t know much about docker and wanted to use a bunch of interactive python notebooks on my machine to use pytorch installed on the docker image.
My plan was to use an existing Pytorch image that comes with a bunch of other python packages (as an image) and run my local python files on that image without installing Pytorch or any other dependencies on my machine.
This can be done using Docker. The existing Pytorch docker image can be accessed for free here. And then I just needed to figure out a way to connect my local files to the docker image and tell my files to use python packages from that image.
Here is how:
0- you need to have docker installed (tutorials here)
1- Open a terminal (powershell in windows is a good choice)
In this tutorial, I use the docker for windows and hence the terminal I use is the windows powershell. Similar instructions can be followed for linux and MacOS.
2- pull the docker image for pytorch
docker pull pytorch/pytorch
3- run the docker image
docker run -it --name pytorch1 -v current_dir_including_ipynb_files:/workspace -p 5000:8888 -p 5001:6006 pytorch/pytorch
- –name gives a name to the container rather than a random one
- -v maps the folder in the local machine to a folder inside the container (mounts the first path to the second – divided by the : symbol )
- -p defines the ports on the local machine and the container
4- if the docker runs correctly, you should be inside the workspace folder of the container
root@ca09f087f880:/workspace#
5- if the mounting is done correctly you should see all the files in the local folder inside the workspace folder
root@ca09f087f880:/workspace# ls
file1.ipynb file2.ipynb
7- check the installed packages in the container
pip freeze
6- the pytorch does not come with the jupyter package and you need to install it
pip instal jupyter
7- Now you want to start the jupyter notebook inside the container but it needs to talk to the local machine
jupyter notebook --ip 0.0.0.0 --port 8888 --allow-root &
8- This gives you a link that you can put into your browser to access the notebook
root@ca09f087f880:/workspace# [I 19:03:50.503 NotebookApp] Writing notebook server cookie secret to /root/.local/share/jupyter/runtime/notebook_cookie_secret
[I 19:03:50.813 NotebookApp] Serving notebooks from local directory: /workspace
[I 19:03:50.814 NotebookApp] The Jupyter Notebook is running at:
[I 19:03:50.814 NotebookApp] http://(ca09f087f880 or 127.0.0.1):8888/?token=643e3ac56e3de36398e7e9c27bc4e61b9b8158aab0d4c1f9
[I 19:03:50.814 NotebookApp] Use Control-C to stop this server and shut down all kernels (twice to skip confirmation).
[W 19:03:50.819 NotebookApp] No web browser found: could not locate runable browser.
[C 19:03:50.819 NotebookApp]
To access the notebook, open this file in a browser:
file:///root/.local/share/jupyter/runtime/nbserver-43-open.html
Or copy and paste one of these URLs:
http://(ca09f087f880 or 127.0.0.1):8888/?token=643e3ac56e3de36398e7e9c27bc4e61b9b8158aab0d4c1f9
9- you need to replace the port before using the url
change 127.0.0.1:8888 into 127.0.0.1:5000 and everything should work correctly.
10- Copy and paste the modified url into your browser and you should see something like this:

Stop the docker
1- exit from the container by pressing ctr+p, ctrl+q in the powershell
2- get the container ID using
docker ps
or
docker ps -l
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
162ccf9ac9dc pytorch/pytorch "/bin/bash" 31 minutes ago Up 31 minutes 0.0.0.0:5001->6006/tcp, 0.0.0.0:5000->8888/tcp pytorch1
3- stop the container using
docker stop 162ccf9ac9dc
4- remove the docker using
docker rm 162ccf9ac9dc
Important Note:
Every time you run the docker, you need to install the additional dependencies (in this case, Jupyter) because the container is actually an image and cannot save changes.


 about a given axis of rotation denoted by
about a given axis of rotation denoted by 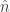 by
by  radians.
radians.
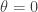 that will result in
that will result in
![v=[2,0,0]](https://s0.wp.com/latex.php?latex=v%3D%5B2%2C0%2C0%5D&bg=ffffff&fg=333333&s=0&c=20201002) about
about ![\hat{n}=[0,0,1]](https://s0.wp.com/latex.php?latex=%5Chat%7Bn%7D%3D%5B0%2C0%2C1%5D&bg=ffffff&fg=333333&s=0&c=20201002) by
by  .
. , where
, where  and
and  and
and  . Also, we consider
. Also, we consider 

![v=[0,0,1]](https://s0.wp.com/latex.php?latex=v%3D%5B0%2C0%2C1%5D&bg=ffffff&fg=333333&s=0&c=20201002) about axis
about axis ![\hat{n}=[0,1,0]](https://s0.wp.com/latex.php?latex=%5Chat%7Bn%7D%3D%5B0%2C1%2C0%5D&bg=ffffff&fg=333333&s=0&c=20201002) by
by  .
.![v_q = [0,v] = k](https://s0.wp.com/latex.php?latex=v_q+%3D+%5B0%2Cv%5D+%3D+k&bg=ffffff&fg=333333&s=0&c=20201002)
![n_q = [0,\hat{n}] = j](https://s0.wp.com/latex.php?latex=n_q+%3D+%5B0%2C%5Chat%7Bn%7D%5D+%3D+j&bg=ffffff&fg=333333&s=0&c=20201002)

 .
.![v = [1,0]](https://s0.wp.com/latex.php?latex=v+%3D+%5B1%2C0%5D&bg=ffffff&fg=333333&s=0&c=20201002) by
by ![v^{'} = e^{\pi/2 i} v = [\cos(\pi/2), i \sin(\pi/2)][1, 0i] =[0, i]](https://s0.wp.com/latex.php?latex=v%5E%7B%27%7D+%3D+e%5E%7B%5Cpi%2F2+i%7D+v+%3D+%5B%5Ccos%28%5Cpi%2F2%29%2C+i+%5Csin%28%5Cpi%2F2%29%5D%5B1%2C+0i%5D+%3D%5B0%2C+i%5D&bg=ffffff&fg=333333&s=0&c=20201002)
![v^{'} = [0, i]](https://s0.wp.com/latex.php?latex=v%5E%7B%27%7D+%3D+%5B0%2C+i%5D&bg=ffffff&fg=333333&s=0&c=20201002) towards Y-axis (Im axis).
towards Y-axis (Im axis).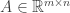 and
and  then
then 





 is a linear function,
is a linear function, ,
,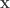 is a random variable,
is a random variable,  and
and  are a matrix and a vector respectively that form the linear transformation. If we calculate the mean and covariance for the transformation, we get:
are a matrix and a vector respectively that form the linear transformation. If we calculate the mean and covariance for the transformation, we get:![\mathbb{E}[\textbf{y}]=\mathbb{E}[\textbf{Ax+b}]=\textbf{A}\mu+\textbf{b}](https://s0.wp.com/latex.php?latex=%5Cmathbb%7BE%7D%5B%5Ctextbf%7By%7D%5D%3D%5Cmathbb%7BE%7D%5B%5Ctextbf%7BAx%2Bb%7D%5D%3D%5Ctextbf%7BA%7D%5Cmu%2B%5Ctextbf%7Bb%7D&bg=ffffff&fg=333333&s=0&c=20201002)
![\mu=\mathbb{E}[\textbf{x}]](https://s0.wp.com/latex.php?latex=%5Cmu%3D%5Cmathbb%7BE%7D%5B%5Ctextbf%7Bx%7D%5D&bg=ffffff&fg=333333&s=0&c=20201002)
![cov[\textbf{y}]=cov[\textbf{Ax+b}]=\textbf{A}\Sigma\textbf{A}^T](https://s0.wp.com/latex.php?latex=cov%5B%5Ctextbf%7By%7D%5D%3Dcov%5B%5Ctextbf%7BAx%2Bb%7D%5D%3D%5Ctextbf%7BA%7D%5CSigma%5Ctextbf%7BA%7D%5ET&bg=ffffff&fg=333333&s=0&c=20201002)
